黄杰, 2013-03-20
root[a]linuxsand.info
2013-11-24 更新:百度音乐推出客户端,内建批量下载。(客户端非常卡)
2013-07-14 更新:歌曲下载链接已改为 pan.baidu.com 提供。脚本失效。
2013-06-06 更新:需要登录百度账号才能在百度音乐下载标准音质的 mp3,所以之前做的网站已经失效。本文失效的内容已删除,保留修改后仍然可用的脚本。
一个可行的办法:1. 登录后获取 cookie[注](我把 cookie 保存在 c:\baiducookie.txt 里);2. 在每次 HTTP 请求中传递 cookie。下面是我用 python 写的脚本。
# coding: utf-8
import urllib
import urllib2
import re
import os
import sys
import time
from bs4 import BeautifulSoup as soup
# 配置正则
song_url_regx = re.compile(r'http://zhangmenshiting\.baidu\.com/data\d*/music/\d+/\d+\.mp3\?xcode=\S{32}')
# 配置 opener
cookie = open('c:\\baiducookie.txt').read()
opener = urllib2.build_opener()
opener.addheaders = [('Cookie', cookie)]
urllib2.install_opener(opener)
# 功能函数
def to_better_name(song_name):
ext = os.path.splitext(song_name)
name = song_name.rstrip(ext)
# from Python doc
return re.sub(r"[A-Za-z]+('[A-Za-z]+)?",
lambda mo: mo.group(0)[0].upper()+mo.group(0)[1:].lower(),
name) \
+ '.' + ext
# 开始抓取、分析
def fetch_album_page(album_url):
page = urllib2.urlopen(album_url).read()
album_page = soup(page)
# type: unicode
album_name = album_page.find('h2', class_='album-name').text
singer_name = album_page.find('span', class_='author_list').text.strip()
assert album_name is not None and singer_name is not None
print u'专辑名:', album_name
print u'歌手:', singer_name
return page, album_name, singer_name
def find_songs_in_album(album_page):
# /song/8783235" title="The Times They Are A-Changin'"
li = re.findall(r'/song/\d+#\S+" title=".+?"', album_page)
song_path_and_name = []
for i in li:
path, song_name = i[:-1].split('" title="')
path = path.split('#')[0]
print path
# 百度音乐奇葩嘛
song_name = song_name.replace('’ ', "'")\
.replace('’', "'")\
.replace('` ', "'")\
.replace('`', "'")\
.replace('?', '?')\
.replace('\\', '\')\
.replace('/', '/')\
.replace(':', ':')\
.replace('*', '')\
.replace('<', '<')\
.replace('>', '>')\
.replace('|', '')
song_path_and_name.append((path, song_name+'.mp3'))
# [(/song/32321, songname1), (, ), ...]
print u'歌曲数目:', len(song_path_and_name)
return song_path_and_name
def get_song_urls(songs):
print 'calling get_song_urls'
song_url_and_name = []
for i in songs:
# i = (/song/4324, songname)
time.sleep(2)
print u'等 2 秒……'
song_page = urllib2.urlopen('http://music.baidu.com%s/download' % i[0]).read()
song_url = song_url_regx.findall(song_page)[0].replace('\\', '')
song_url_and_name.append((song_url, i[1]))
return song_url_and_name
# 下载
def download(song_url_and_name):
for url, name in song_url_and_name:
if not os.path.exists(name):
code = urllib2.urlopen(url).getcode()
name_ = to_better_name(name)
if name_ != name:
u_name = unicode(name, 'utf8')
u_name_ = unicode(name_, 'utf8')
print u'重命名 %s 为 %s' % (u_name, u_name_)
if code == 200:
print u'正在下载 %s' % u_name_
if os.path.exists(u_name_) and \
long(urllib.urlopen(url).info()['Content-Length']) == \
os.stat(u_name_).st_size:
print u'提示:%s 已经存在,不再下载' % u_name_
else:
urllib.urlretrieve(url, u_name_)
else:
print u'错误码:', code
if __name__ == '__main__':
url = sys.argv[1]
page, dir_name, singer = fetch_album_page(url)
dir_name = dir_name.encode(sys.getfilesystemencoding())
songs = find_songs_in_album(page)
urls = get_song_urls(songs)
# 进入 Music 目录
os.chdir('c:\\users\\administrator\\music')
# 建立「艺人」目录,存在则进入
if not os.path.exists(singer):
os.mkdir(singer)
os.chdir(singer)
else:
os.chdir(singer)
# 建立「专辑」目录,存在则进入
if not os.path.exists(dir_name):
os.mkdir(dir_name)
os.chdir(dir_name)
else:
os.chdir(dir_name)
download(urls)
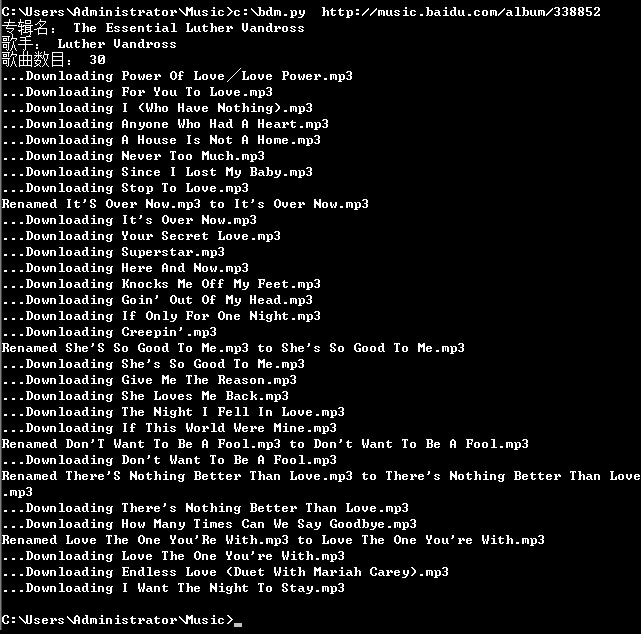
效果图:
*[注]: 以 Chrome 为例,开发者工具(F12) - Network - Headers - Request Headers - Cookie